Review 《Using pipelining to speedup Redis queries》
Redis Pipelining 是什么
在理解 Redis Pipelining 之前,我们需要先弄明白,Redis 是如何执行客户端的命令的。Redis 是一个 TCP 服务器,它和客户端之间通过网络进行通信。当我们在客户端中执行了一条命令后,Redis 通常会执行以下的操作:
- 客户端获取 TCP 连接。(新建连接或者获取已有的连接)
- 客户端发送一个 Redis 命令给服务端。
- 客户端等待读取服务端的响应,并阻塞起来。
- 服务端处理客户端的命令,并将命令的响应发送给客户端。
如果我们要执行4个set命令,那么客户端就会通过 TCP 网络发送4个请求包,接受4个响应包。
因为 Redis 服务器处理命令的速度通常都是很快的,很多时候时间都是花在了网络IO 上,所以我们可以将多个命令合并成一个网络请求,然后 Redis 服务器会 按顺序 返回这 N 个命令的响应。
构造一个 Pipelining 请求
由于 Redis 的通信协议是基于文本的,所以我们可以直接通过 nc 向 Redis 发送一个 Pipelining 请求。
在下面的例子中,我们向 Redis 服务器发送了两条 INCR 命令,它也 按顺序 返回了这两条命令的响应:
ø> printf "INCR 'some_key'\r\nINCR 'some_key'\r\n" | nc localhost 6379
:1 // 这是第一条命令的响应
:2 // 这是第二条命令的响应
使用 Pipelining 的注意事项
当客户端使用 Pipelining 的方式发送多个命令过来时,Redis 服务器将会使用内存对响应进行排队(个人猜测对响应结果的排序也是在内存中进行的)。 所以 Pipelining 请求中不要包含太多的命令,否则会吃服务器很多内存,官方给的建议是一个 Pipelining 请求中最多有 10K 个命令。
使用 Pipelining 的好处
客户端的响应时间更短
下面是一个简单的压测程序(完整代码见 GitHub),对比使用 Pipelining 和不使用 Pipelining 的执行时间:
func PingWithPipelining(rdb *redis.Client, ctx context.Context) {
_, err := rdb.Pipelined(ctx, func(pipeliner redis.Pipeliner) error {
for i := 0; i < benchTimes; i++ {
pipeliner.Ping(ctx)
}
return nil
})
if err != nil {
log.Printf("%v\n", err)
}
}
func PingWithoutPipelining(rdb *redis.Client, ctx context.Context) {
for i := 0; i < benchTimes; i++ {
_, err := rdb.Ping(ctx).Result()
if err != nil {
log.Printf("%d: %v\n", i, err)
}
}
}
func main() {
for _, tt := range []struct {
Name string
Callback TestRedisFunc
}{
{
Name: "WithPipelining",
Callback: PingWithPipelining,
},
{
Name: "WithoutPipelining",
Callback: PingWithoutPipelining,
},
} {
fmt.Printf("Start %v\n", tt.Name)
duration := Benchmark(tt.Callback)
fmt.Printf("%v Running %d times cost %v\n", tt.Name, benchTimes, duration)
}
}
程序的输出如下:
ø> go run redis_pipelining.go
Start WithPipelining
WithPipelining Running 10000 times cost 9.596085ms
Start WithoutPipelining
WithoutPipelining Running 10000 times cost 263.630767ms
在我的电脑上(双核+8G)上,使用 Pipelining 的函数的执行时间比不使用 Pipelining 的函数低了两个数量级。
提升服务器的性能
使用 Pipelining 不仅会节省客户端的执行时间,也会提升服务器的性能。设想一下这两种的情况:
- A: 客户端执行了10000次的 set 命令
- B: 客户端通过 Pipelining 执行了 10000 次的 set 命令
在 A 场景下,服务器相比 B 场景多执行了很多的网络IO(读取请求和发送响应)。因为服务器的计算资源(CPU,内存)用在处理网络 IO 上了,它处理客户端查询的能力就变差了。
这是官方给的性能曲线:
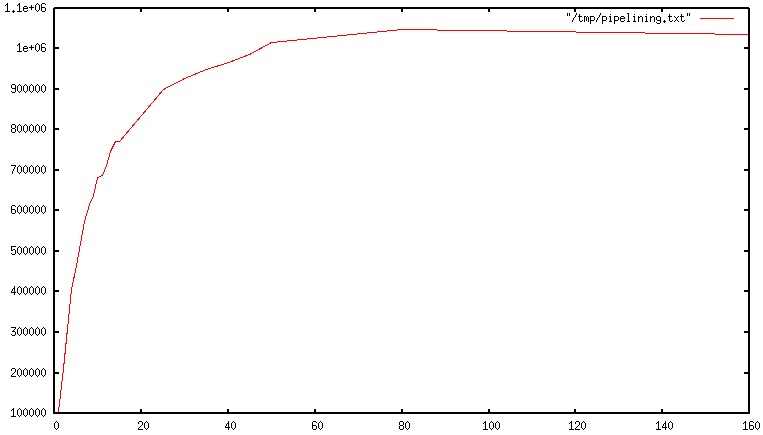
横坐标是单次请求中包含的命令数,纵坐标是服务器每秒能够处理的查询数。可以看到客户端使用了 Pipelining 后,服务器每秒能够处理的请求数几乎达到了原来的10倍。
其他
文中还有两段内容,
- Lua 脚本是比 Pipelining 更好的选择,因为在脚本中可以执行一定的逻辑,这样计算就可以完全放在服务端做了,网络通信更少。(个人吐槽,坏处就是开发成本变高了)
- 为什么在环回接口执行压测程序,请求还是这么慢,作者的建议是不要将压测程序和服务器放在同一台机器上,因为压测程序也会占用主机的资源,这也会影响服务器的性能。